-
A system for downloading, storing and analysing web pages
-
Use cases
- Search engine indexing
- Web archiving
- Web monitoring for copyright or trademark violation
-
Steps,
Given a list of seed URLs -> Visit each URL -> store the web page -> Extract URLs from the current page -> Append the URLs to the list of URLs to visit -> repeat
-
Characteristics of a good web crawler,
- Should be scalable
- Should be robust enough to handle poorly formatted HTML, malicious sites, crashes, etc.
- Should avoid making too many requests to a website in a very short time as it might lead to a DDoS attack
- Should be extensible for future changes
Overview
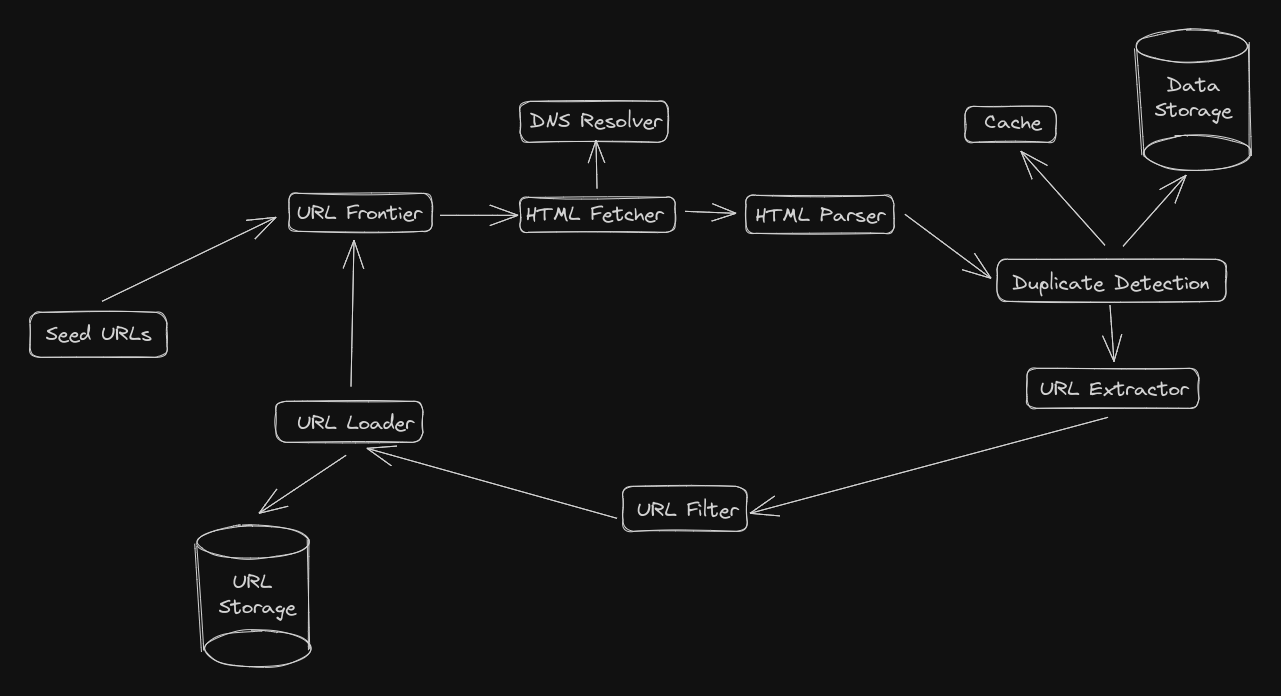
Seed URLS
- Initial links that are used at the starting point of the crawling process
- Choosing the right URLs can impact the number of web pages crawled
URL Frontier
- A queue data structure that holds the URLs that have to be fetched and analysed
HTML Fetcher
- Downloads the web page pointed by the URL given by the URL frontier
DNS Resolver
- Translates the URL to the web-page’s IP address
HTML Parser
- Check integrity of a web page’s data
- Checks for poorly formatted HTML and malware
Duplicate detection
- Storing duplicated leads to unnecessary space usage and slow down the system
Cache
- To improve web crawlers efficiency
- Stores most recently crawled URLs
Data Storage
- The web page’s data is stored in a storage system
URL Extractor
- Extracts URLs from the current HTML page
URL Filter
- Filters out faulty or malicious URLs
URL Loader or Detector
- Filters out URLs that have already been visited
- Bloom filters are commonly used (Why? extremely space efficient when compared to hash tables at the cost of missing out on some of the URLs)
URL Storage
- Keeps track of all the visited URLs